A. K. Dewdney
Deductive and Inductive Science:
Reflections, Memories, & Open Problems
I have spent the better part of my adult professional life as a researcher
in the area of deductive science. I should, at the outset, explain that
all science may be divided into two great branches: deductive and inductive.
In deductive science we explore the space of necessary conclusions that flow from axioms through the application of logic. The conclusions are, shall we say, unavoidable and without exceptions. A trivial example will illustrate precisely what I mean. One might prove the following statement by applying deductive logic (which has its own axioms) to the axioms of the natural numbers:
Theorem: The sum of every two odd numbers is even.
"In the other great branch, inductive science, we seek statements that are generally true (just as theorems are generally true), but we recognize at the outset that such statements, except in rather exceptional cases, can never be proved in the mathematical sense. Instead, because they are statements about the real world, we seek confirmation in the evidence provided by the real world itself. Galileo, for example, declared that all bodies accelerate at the same rate in a vacuum. There is no way to prove this statement as a mathematical proposition about reality, since we do not have a complete mathematical description of reality (and probably never will). Nevertheless, Galileo could test his statement by measuring acceleration due to gravity for a variety of different bodies and demonstrating that the acceleration was independent of the material composing the body.
Strictly speaking, these experiments only confirmed the statement for the materials in question and (a purist might add) for the period of time over which the experiment was conducted. In other words, Galileo's experiments, like all experiments since, can only contribute to the weight of evidence in favor of an hypothesis. They can never confirm it absolutely in the way that a mathematical proof can confirm the truth of a mathematical statement.
In fact, the real value of experiments lies in their power to disconfirm statements or hypotheses. A single experiment that does not accord with the hypothesis will kill it. Strictly speaking, inductive science progresses by retaining all the hypotheses that have yet to be disproved by experiment.
In spite of what, to the mathematician's eyes, are such grave shortcomings, I have been venturing into inductive science for the last few years, principally the biology of populations and communities, a field that is at a rather primitive state of development. (See biodiversity.)
Here, I will recount some highlights and lowlights of my development as a deductive scientist. In order to introduce the problems that have fascinated me most, it helps to recount my own story, one that differs only in detail from those of thousands of other scientists."
PhD days
"In graduate school at the University of Michigan, I studied topology, a subject whose modern, amorphous flavor appealed to me. Although R. H. Bing had already left in 1965, there were several strong mathematicians still there, including Halmos, Lyndon, Raymond, and Wilder, among others.
I particularly enjoyed Frank Raymond's lectures. He had a mind like a freight train. It took so long to pull out of the station that you'd think he was stupid. His heavy-lidded eyes only added to the effect. But he would gradually speed up, becoming unstoppable once up to speed. Raymond would draw an exact sequence on the board or a commutative diagram and a student might ask, "How do you know the mapping on the right is onto?" Raymond would blink, as though he'd never heard of an exact sequence. He'd hem and haw, pull out a typical element of the mapped-into set, examine it, slowly derive its basic property, one that would ensure it was an image element, then go on to derive a similar property for all the sets of the diagram, then he would lift the entire commutative diagram into a covering space and derive some exotic property of the space itself, all from an innocent question. Every question, even a stupid one, was well-repayed in Raymond's classes.
By the time I got to cohomology and fibrations, modern abstract topology was beginning to lose much of its appeal. The level of generality was so great, it was like breathing rarified air. This deterred a number of us from pursuing topology further. A few of us migrated into what some mathematicians sneeringly (at the time) referred to as the "slums of topology," namely graph theory in its topological context. In fact the topological side of graph theory, almost trivialized by its one or two dimensions, was merely one facet of the more general area that I may as well call " discrete mathematics ". At that very time, discrete mathematics was rapidly blossoming, thanks to its fertilization by computer science.
Initially, I worked under Frank Harary, a larger-than-life character that everyone in discrete mathematics knew or knew of. Harary was energetic, ambitious, and engaging. He loved to conjecture things and urge his grad students to investigate. Any paper that emerged from the inquiry would bear both names. Thus Harary's little department-within-the-department hummed like a paper factory.
At first, Harary liked my idea of working on topological embeddings of graphs (like networks) into two-dimensional orientable surfaces, namely the n-holed tori. However, results were hard to come by and, suddenly. two mathematicians called Ringel and Youngs proved the conjecture I had been working on."
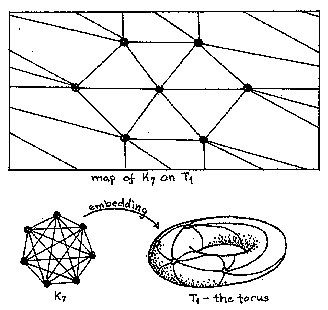
In mathematics (and deductive science generally) a "conjecture" plays the same role as an "hypothesis" does in inductive science. It is a statement which you think is true but cannot yet prove. For example, the famous four color theorem was at this time only a conjecture and a few students had caught the "disease" of trying to prove it. During this era, Martin Gardner, then writing for Scientific American, would receive a new "proof" of the four color conjecture in the mail practically every week. These proofs were usually from amateurs who misunderstood the statement of the conjecture itself, but I digress.
The conjecture that Ringel and Youngs proved stated that a complete graph of order n could be embedded in the m-holed torus, where
-
m = {(n-3)(n-4)/12},
where "{}" represent the least integer function. In spite of this setback, however, I was able, however, to explore and completely solve a similar problem involving pseudo 2-manifolds, analogs of two-manifolds in which the "holes" had been pinched down to points, like old fashioned upholstering. The general result I obtained became my first published paper, which appeared in a humble journal called Manuscripta Mathematica. (The chromatic number of a class of two-manifolds, Manuscripta Math. 6 (1972), 311-319.)
My thesis had evaporated before my eyes. Harary suggested that I have a go at generalizing graph theorems to higher dimensional objects called "complexes." This problem area, while it never appealed to me enough to obsess, nevertheless led to a slow trickle of results that increased over the next few years.
My first academic appointment
In the meantime, I had been offered a job at the University of Western Ontario Department of Computer Science on the basis of the mere promise that I would, eventually get my PhD. To make life a little easier, I transferred to the University of Waterloo, just down the road and a lot more convenient place to visit. Leaving the volatile Frank Harary and hooking up with the reserved Crispin St John Nash-Williams, himself an eminent discrete mathematician, was like stepping out of a warm bath into a cold shower.
Nash-Williams was the quintessential Oxford don type. I came to appreciate, nevertheless that he actually had a great sense of humour. But he deployed it only on occasion, not indiscriminately, as Harary did. I worked for three years, teaching at Western and sending draft after draft of my thesis to Nash-Williams. The drafts always came back with approximately twice as much paper as I had sent, covered with Nash-Willliams' detailed comments, from points of grammar to full-blown re-workings of proofs.
Finally, in exasperation, I went to him, asking whether he thought I might be getting close to completion. His reply still rings in my ears: "Well, Dewdney, I don't suppose it is the sort of thesis that an examining committee is likely to reject out of hand." I left his office, crestfallen.
At lunch I explained to my friend, Adrian Bondy, what Nash Williams had said. Perhaps, as an Englishman, Bondy might offer a translation. "Ah, well done, Dewdney. You've finished then!"
With my PhD in hand, I was immediately promoted from lecturer to assistant professor and the future looked a little more secure. I decided to publish some of the better results from my thesis. In the first of these, I had generalized the graph-theoretic notion of connection in three different ways, one involving essentially one-dimensional structures, the other two involving structures of arbitrarily high dimension. (Three species of connection in complexes, Stud. Sci. Math. Hung. 9 (1974), 331-339.)
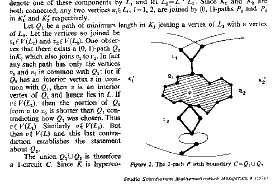
Next, I generalized the notion of a tree structure to higher dimensions, using the same three ideas of higher-dimensional connection. (Higher dimensional tree structures, J. Comb. Th. 17 (1974), 160-169.) The second journal was one of the best in the field. I felt as though I was beginning to "arrive," as they say.
In a graph (essentially a one-dimensional complex), the degree of a vertex is the number of edges with which it is incident. If you write down the degrees of any graph in descending order, you get a sequence of numbers. What sequences of numbers were degree sequences? The question had already been answered in several ways in graph theory. I simply generalized them and was able to tell anyone who asked whether a given sequence of numbers belonged to an n-complex or not. (Degree sequences in complexes and hypergraphs, Proc. Am. Math. Soc. 53 (1975), 535-546.)
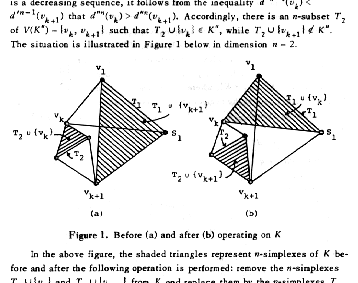
When two vertices of a graph share an edge, they are said to be adjacent. By replacing every edge of a graph by a new vertex and making two such vertices adjacent if their corresponding edges shared a vertex, one obtains a new graph called an adjacency graph. There were already characterizations of adjacency graphs for graphs themselves, but nothing for higher-dimensional complexes. I found new characterizations of this type. I published the result jointly with Harary. Up to this point, I had tried to avoid this since, in my view, Harary had contributed nothing toward the solutions of previous problems. Normally, he insisted on publishing jointly with all of his graduate students. In any event, I was no longer his student and hadn't been for several years. (The adjacency graph of a complex, Czech. Math. J.26 (1976), 137-144 (with F. Harary).)
To round out this sequence of papers, I published a few other graph-theoretic generalization having to do with the intersection numbers of a complex. (The intersection numbers of a complex, Aeq. Math. 14 (1976), 357-362.) I would publish two more joint papers with Harary, since he actually contributed to the problems involved. In the first case, we worked together in deciding what the appropriate generalization for a directed graph should be, namely an oriented complex, a key concept in distinguishing orientable manifolds from non-orientable ones. (Oriented, two-dimensional circuits, Discrete Math. 33 (1981), 149-163 (with F. Harary).) The second paper involved generalizations of coloring graphs to coloring complexes. (On the chromatic numbers of a simplicial complex, J. Comb. Inf. and Sys. Sci. 2 (1977), 28-35 (with F. Harary).)
During my early years at Western, I worked on a few problems of my own in graph theory, although I never regarded myself as a graph-theorist, per se. For example, I wondered, as a general proposition, whether graphs could be combined to produce new graphs, somewhat as numbers are. I found a way to combine graphs that led directly to a most intriguing idea, that of building all graphs out of a few simple ones that were themselves irreducible in this sense. The result had a flavor that was similar to the theory of group representations. In analogy with the prime numbers, I called the irreducible graphs "primal."
I established the primal graph theorem, which proved the existence of a primal set. (Primal Graphs, Aeq. Math. 4 (1970), 326-328.) I had great fun deriving the primal graphs, something that got increasingly hard as one went to higher and higher orders. I was joined in this endeavour for a while by Phyllis Chinn, a mathematician I met at one of the popular Southeastern Conferences.
One day in the 1970s, Julian Davies asked what was the longest sequence one could input to an automaton before it would be forced to use the same transition twice. Since the question was asked over the set of n-state automata, it was simply a case of finding such a class and proving optimality. Andy Szilard helped with the optimality proof. I will never forget the look of shock on his face when I announced that the paper had been accepted by the IEEE Transactions on Computing. You'd think he had never published a paper before! (Tours in machines and digraphs, IEEE Trans. Comput. 7 (1973), 635-639 (with A. L. Szilard))
Just once during the 1970s I returned to topological graph theory, an indulgence that was becoming increasingly rare, as I attempted to publish as much as possible in computer science at the time. I did succeed in extending Wagner's theorem for the plane to the torus. This theorem says that any triangulation of a plane graph on n vertices can be obtained from any other by just one kind of operation. Two triangles that share an edge form a quadrangle. Remove the shared edge and insert the opposite diagonal. The theorem was somewhat tricky and made me more aware than ever that long proofs may be suspect well after everyone else has accepted them. In reading the proof over, one subtlety would elude me for about ten minutes until I " got it " . Next day I would have to start all over! (Wagner's theorem for torus graphs, Discrete Math. 4 (1973), 139-149.)
Among the computer science oriented papers I wrote during this period was one that combined both computers and graph theory. I worked out an algorithm for generating a complete list of graphs on n points, rejecting isomorphic duplicates as it went. There was a particularly useful form of signature, involving the lexicographical listing of a code for the graph. Szilard joined me in the generation process, along with a grad student Harlan Baker, who did the actual coding. Together we produced a complete list of the nine-point graphs. The best anyone had done before this was the generation of the 8-point graphs by Reid at Waterloo. Baker went on to do his graduate work in AI at Edinburgh. (Generating the nine-point graphs, Math. Comp. 28 (1974), 833-838 (with H. H. Baker and A. L. Szilard))
Finding my feet
By the mid-seventies I was encountering more and more problems that combined discrete mathematics and computing. This was natural because both computers and graphs have a discrete structure. Many data structures were natural targets for algorithms designed to test them for various properties or to manipulate them in some way. One very interesting problem called for an assignment of integers to the vertices of a graph so as to minimize the maximum difference along any edge. This problem, which I could solve only in various special cases, was about to be proved NP-complete, which pretty well doomed it forever to inefficient solution algorithms.
I presented a number of results at one of the Southeast Graph theory and Computing conferences. (The bandwidth of a graph: some recent results, Proc.7th S.E.Conf on Graph Th., Comb. and Comput. Baton Rouge, La. 1976, 273-288.)Before I knew it, I was back working with Phyllis Chinn, as well as Bob Korfhage, Norman Gibbs, and Jarmilla Chvatalova. (Graph bandwidth: a survey of theory and applications, J.Graph Th. 6 (1982), 223-254 (with P. Z. Chinn, J. Chvatalova, and N. E. Gibbs). I enjoyed the bandwidth problem because it had this unusually urgent application in engineering. If you knew the bandwidth of a graph you could set up the stress matrices for towers, bridges, ship hulls and other structures in a way that would greatly reduce the time needed to analyze them by computer.
I use the phrase "unusually urgent" as a kind of joke. By the end of the 1970s I had attended too many talks where mathematicians would speak of "applications," only to reveal the most pathetic and trivial relations with the real world imaginable! I tried to avoid this sort of "application" altogether, especially if I felt obliged to invent an application to make my paper look more relevant. I had been raised (in my early mathematics program) with the view of G. H. Hardy that any mathematics that could possibly be applied wasn't worth doing. I realized how snooty that sounded on the surface, but I appreciated what it meant: REAL mathematics exists in and of itself, shrouded by its own beauty, giving itself only to the ardent suitor. I was a platonist. I still am.
Everyone knows that a graph can be embedded in Euclidean 3-space. In other words, there is no particular difficulty connected with placing the vertices and adding edges so that no two edges touch each other. But do this in such a way that all the edges are straight. Again, the problem seems easy, except when you try to provide a general recipe for doing this. An elegant solution to this problem (Embedding graphs in Euclidean three-space, Am. Math. Monthly 84 (1977), 372-373).arose as the by-product of another solution to another problem.
.JPG)
I had solved a difficult problem posed by Donald E. Knuth, the so-called post-office problem. Construct a database that would enable an algorithm to decide in linear time the closest post-office to which mail should be routed. My solution, which involved Voronoi diagrams, was published by someone else shortly after I discovered it. This meant, among other things, that they had discovered it first.
At the same time, I had become fascinated by colorings of three-dimensional maps, asking a question that any undergraduate could readily answer: What is the maximum number of three-dimensional ��countries�� you can have in a three-dimensional map (arrangement) so that each country touches all the others? Of course, the answer is that there is no limit. You may have as many countries as you want. But what if all the countries have to be convex? (Crum's Problem) I struggled with this problem for a while, mentioning it to my friend John Vranch who was just finishing his PhD at Waterloo. Vranch came up with a brilliant solution that involved placing n vertices at integer points on the polynomial (x, x2, x3), then making the vertices centres in a three-dimensional Voronoi diagram. Still smarting from the loss of my post-office solution, I insisted on bringing it into our joint paper on the problem (Convex partitions of R3 with applications to Crum's problem and Knuth's post-office problem, Utilitas Math. 12 (1977), 193-197 (with V. K. Vranch)). At the same time, I realized that the same polynomial provided an elegant solution to the problem of graph embedding in 3D.
The neural net assignment problem
Almost from the moment of my arrival at Western, I had fallen in love with Marvin Minsky's early computer science text, Computation, Finite and Infinite Machines. I was particularly intrigued by neural nets, the old fashioned kind formulated by McCullough and Pitts in the 1940s. I was impressed by the equivalence of neural nets with finite automata. (Equivalences fascinate me in general, a theme I will return to soon.) Every neural net defined a finite automaton and every finite automaton could be simulated by (was equivalent to) a neural net.
 The
interesting thing here was that you could always replace an n-neuron net by an automaton
that had 2n states. It seemed logical, going in the other
direction, to replace an n-state automaton by a net that had in the order of
log(n) neurons. The best I could do, however, was a net with in the order of n3/4 neurons which, in comparison with the logarithm
goal, seemed pathetic. To interest others in what seemed to me a rather
fundamental problem, I presented a progress report at what had become my
favorite conference (always being held in the US south during the Canadian
winter). (Threshold matrices and the state-assignment problem for neural nets, Proc. 8th S. E. Conf on Graph Th,, Comb. and
Comput. Baton Rouge, La. 1977, 227-245.)
The
interesting thing here was that you could always replace an n-neuron net by an automaton
that had 2n states. It seemed logical, going in the other
direction, to replace an n-state automaton by a net that had in the order of
log(n) neurons. The best I could do, however, was a net with in the order of n3/4 neurons which, in comparison with the logarithm
goal, seemed pathetic. To interest others in what seemed to me a rather
fundamental problem, I presented a progress report at what had become my
favorite conference (always being held in the US south during the Canadian
winter). (Threshold matrices and the state-assignment problem for neural nets, Proc. 8th S. E. Conf on Graph Th,, Comb. and
Comput. Baton Rouge, La. 1977, 227-245.)
This began a collaboration that lasted several years. I was invited to visit Teunis J. Ott at Bellcore research in Morristown NJ. Ott and I wrestled the exponent down over the years, but it took a colleague of Ott's at Bellcore, Noga Alon, to prove that the best we could expect to do was an automaton with in the order of _n states. ( On the efficient simulation of finite automata by neural networks, J. A. C. M. vol 38 #2 (1991), 495-514 (with N. Alon and T. J. Ott)).
Outside my area
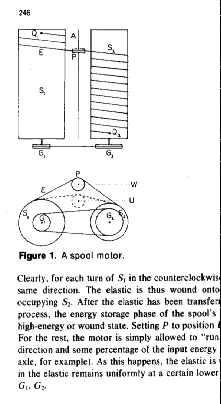 During the 70s I pursued a few one-off projects in engineering, astronomy,
and other areas. The mechanical invention of which I am proudest is the
spool motor. True Platonist that I am, I never pursued a patent for this
device. It consists of two spools of different sizes turning on axles with
meshing gears (1:1 ratio, say) at one end. You then attach one end of a
rubber band to the small spool and wind it onto the spool with a certain
tension T1. You attach the other end to the larger spool and proceed to
turn the mechanism. It winds onto the larger spool with tension T2 >
T1. Since you must do work against the system to achieve this state, you
are storing potential energy. When you release the mechanism, the spools
unwind, feeding all the rubber back onto the smaller spool. To ensure that
the rubber winds back with tension T1, you add a small adjustable pulley
with two positions, one for winding, one for unwinding.
During the 70s I pursued a few one-off projects in engineering, astronomy,
and other areas. The mechanical invention of which I am proudest is the
spool motor. True Platonist that I am, I never pursued a patent for this
device. It consists of two spools of different sizes turning on axles with
meshing gears (1:1 ratio, say) at one end. You then attach one end of a
rubber band to the small spool and wind it onto the spool with a certain
tension T1. You attach the other end to the larger spool and proceed to
turn the mechanism. It winds onto the larger spool with tension T2 >
T1. Since you must do work against the system to achieve this state, you
are storing potential energy. When you release the mechanism, the spools
unwind, feeding all the rubber back onto the smaller spool. To ensure that
the rubber winds back with tension T1, you add a small adjustable pulley
with two positions, one for winding, one for unwinding. I built a working model that functioned well enough to illustrate the complete practicality of the device. Several variations are possible, including equal size spools with a different gear ratio. You can even put both spools on the same axle to save space. The application I had in mind was for a wind-up motor for one of my son's model airplanes. Why should the rubber motor only last ten seconds? A spool motor would give him a flight that lasted over a minute. And a more serious application also suggested itself: Automobiles equipped with a powerful "spring motor" (a tempered steel spring replacing the elastic and wound onto receiving grooves on steel spools) could apply a pre-brake when slowing for a stoplight, not bleeding the momentum out through friction in the braking system, but feeding it directly into the spool motor. The same energy could then be fed straight into the wheels of the vehicle when starting out from a light, saving (over the long run) enormous amounts of energy for every vehicle using such a device.
It is NOT the person who dreams up a new invention who should get the credit, but the person who develops it. This may seem a hard thing, but that's generally how things work out and I agree with it. No matter how good an idea is, it's generally much harder to develop it and make it work than it is to dream it up. It's not really difficult, in my experience to dream up all sorts of good ideas. Putting them to work is another matter altogether. So, you developers, here's the recipe: (Spool motors: compact storage of a stretched elastic medium, Mech. and Mach. Th. 13 (1978), 245-250)
Astronomy. I imagined that somewhere out in the vastness of space, superfast quasars might be blinking. What would the signal look like, given a really massive body and the finite velocity of light? The answer came from undergraduate-level manipulation of an integral, my only publication in astronomy. (A size limit for uniformly pulsating sources of electromagnetic radiation, Astophys. Lett. 20 (1979) 49-52).
A final turn to discrete mathematics
An interesting problem in what might be called discrete structural information theory involved graphs. Given a collection of graph invariants, were these sufficient to uniquely specify the graphs they described? In other words, if I knew the values of these invariants for a graph G, could I be guaranteed that no non-isomorphic graph would have the same values?
The answer obviously depended on the invariants. I defined and investigated the "power" of an invariant to specify graphs, publishing the result at one of the Southeastern Conferences (Three classes of graph invariants and their powers, Proc. 9th S. E. Conf on Graph Th., Comb. and Comput. Boca Raton, Fla. 1978, 243-263).
Practical problems
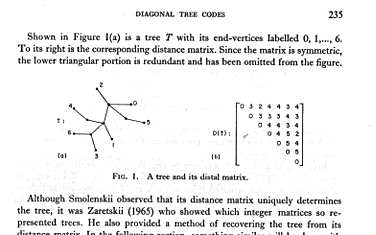
Much of my more serious (i.e., computer science) research work in the late 1970s involved various data structures and algorithms, areas quite close to discrete mathematics. Trees, being ubiquitous objects of storage and retrieval of data, made ideal objects to work with. I was particularly intrigued by the ability of distance matrices to specify trees. In the ijth position of such a matrix, one would enter only the distance between the ith and jth vertices. In fact, all you needed, it turned out, was distances between consecutive end-points when the tree was embedded in the plane. The resulting code was linear in the length of the tree, i.e., quite short and efficient. On the other hand, you got a different code for each embedding of the tree. I needed a unique code.
I did some of this work with Gary Slater, discovering by accident that we were working on the same (unknown) problem. I published the initial work (Diagonal tree codes, Information and Control, 40 (1979), 234-239), then went on to completely solve the problem by finding an optimal code. (An optimal diagonal tree code, SIAM J. Alg and Disc. Math. 4,1 (1983), 42-49). I don't know whether the methods were ever picked up, but they had applications to the efficiency of storing and comparing cladograms, genetic distance trees, and many other biological data structures.
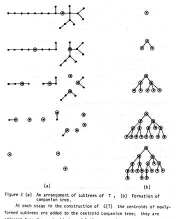
The consecutive retrieval problem involved organizing the entries in a binary matrix so that there would be a minimum number of gaps (consecutive zeros) in the combined columns of the matrix. It is a great advantage to organize a retrieval matrix in this manner, where the 1s represent data that is relevant to a given search and the 0s otherwise. Each column of the matrix represented an aspect of the data on which a search might be conducted. The decision problem turned out to be NP-complete, but I had found a fast, approximate algorithm to solve this problem in most cases (A fast, approximate gap-minimization algorithm, Proc. 10th S. E. Conf. on Graph Th., Comb. and Comput. Boca Raton, Fla, 1979, 349-365).I also found a new way to store arbitrary data trees that was a tad more efficient than most then available, although it took some complicated programming to convert theory into practice. The algorithm I worked out finds the centroid of a tree, then breaks it into pieces, finds the centroids of the pieces, and so on. Even if the original tree is cumbersome to search, the new "companion" tree could always be searched efficiently. (Centroid companion trees, Congressus Numerantium 28 (1980), 351-367).
Artificial intelligence
During the 1970s, I was much fascinated with the burgeoning field of artificial intelligence or AI. I am far less sanguine now about the possibilities with this field and I am still puzzled why Terry Winograd's work (eg. SHRDLU) never got developed into some really fantastic conversational engines. Did it all get too complicated?
How do you find one image in another (face in a crowd?) For some classes of images, the hill-climbing technique gave very good results (Analysis of a steepest-descent image-matching algorithm, Pattern Recog. 10 (1978), 31-39). Also in the field of robot vision, I worked on autonomous robots and their vision problems, publishing the results not in regular journals, but in occasional publications such as (Two low-level vision projects, CSCSI Newsletter, 1 #3 (1976), 37-41) and (Image-matching in the context of a semi-autonomous 'Mars Rover', CSCSI Newsletter 1 #4 (1977), 42-43) I became interested in robotics after building a small autonomous robot of my own which I believe Hans Moravec (one of my students at the time) may still have. (Hardware and software proposal for a small robot, UWO DCS Tech. Rep. #5, Sept 1972).
The general equivalence problem
If I was ever to have a magnum opus (or at least the beginnings of one) it would have been in the area of generic reduction computers, a completely new way to compute based on the famous NP-completeness proof by Stephen Cook in 1974.I say "proof" instead of "theorem" because the proof actually contained a hidden recipe to compute practically anything very quickly, completely eliminating the distinction between NP complete problems and those in P (assuming P does not equal NP). I came to the conclusion that such a computer would be possible during my sabbatical at Oxford University in 1980-81. I published as much as I could on the subject in the next few years, but other events caught up with me and completely sidelined the whole program: I was selected to write a column for Scientific American magazine. The commitment, which lasted until the early 1990s, left me with little or no spare time to pursue generic reduction computers. I would dearly love to see someone take up the reins of this research and investigate these engines of brute-force logic somewhat further.
The research began when I pondered somewhat deeply on the real "meaning" of Cook's theorem. In 1974, Cook, then a grad student at Berkeley, published a stunning paper that revealed the existence of NP-complete problems. The process by which a Turing machine could decide whether a solution proposed for problem A could be checked in polynomial time was itself reducible in polynomial time to an instance of the satisfiability problem. (Problem A being generic) Thus satisfiability became the first "NP-complete" problem. Moreover, every problem to which satisfiability could be reduced in polynomial time was also NP-complete.
The significance of NP-complete problems (and by extension the NP-hard ones) was that a polynomial-time algorithm to solve any NP-complete problem was theoretically convertible to a polynomial-time algorithm to solve any other problem in the set. The trouble was that no one had ever found a P-time algorithm for any of the NP-complete problems. This amounted to the strongest possible evidence that none of these problems were polynomial-time solvable! Over subsequent years, the list of NP-complete problems was extended by hundreds of mathematicians and computer scientists from a few dozen to several thousand. For a few years, the discovery of new NP-complete problems became a veritable cottage industry.
During my first sabbatical (at Oxford University (Merton College and the Math Institute) I first learned to prove Cook's theorem for myself. Then I began to improve on the proof in various ways. What excited me about Cook's theorem was that it was the first evidence I had ever seen for a kind of mathematics that I had long suspected to exist, but had never known how to get started on. It was a mathematics of equivalence, if you will. It is a fascinating phenomenon when two problems, hitherto thought to be unrelated, turn out to be the same or equivalent,. One can find a transformation between that instances (and solutions of same) that map from one problem to the other.
The research took two broad avenues: The first avenue led to P-time equivalence as a phenomenon in its own right. I built large classes of equivalent problems. Some of these were P-time problems, and some were NP-complete. My P-equivalence classes respected the P/NPC boundary, of course. (Linear time transformations between combinatorial problems, Internat. J. Comp. Math. 11 (1982), 91-110), (Fast Turing reductions of combinatorial problems and their algorithms, Proc. 3rd Internat. Conf. on Combinatorics, vol 555 of the N. Y. Acad. of Sciences, 1989, 171-180). I never published the entire set of mutually transformable problems, but they are available in the form of departmental reports: (Fast Turing reductions between problems in NP, UWO DCS Tech. Rep. #s 68-75, 1981-84).
In the other line of research, I investigated Cook's theorem as the basis for a whole new way to compute things. The idea was to reduce all instances of any computable problem whatever into instances of satisfiability. This was done by a transformation engine which could be a suitably programmed general purpose computer. I discovered ways of getting extremely small clause systems to express general problems, meaning that I had minimal-size instances of the satisfiability problem to solve. The second phase of the computation was handled by a satisfiability engine which was simply a hard-wired, Batcher-switched network of many thousand (today a million is do-able) modules that sifted their way through potential solutions in massively parallel mode.
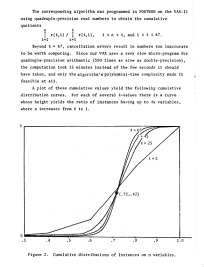
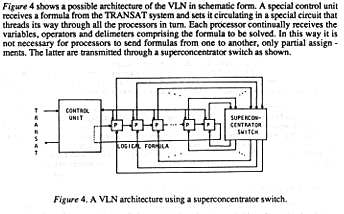 I called this conceptual computer the GRC, short for Generic Reduction Computer.
I thought there was a nice balance in the idea: Let the theorem which proved
the existence of the illness (NP-completeness) provide the cure (the GRC).
I called this conceptual computer the GRC, short for Generic Reduction Computer.
I thought there was a nice balance in the idea: Let the theorem which proved
the existence of the illness (NP-completeness) provide the cure (the GRC).
Naturally, I spent a lot of time finding ways to speed up the solution of the satisfiability problem (Average-time testing of satisfiability algorithms, Congressus Numerantium 39 (1983), 305-325 (with T. R. S. Walsh and D. L. Wehlau)), (A methodology for average-time testing of graph algorithms, Congressus Numerantium 47 (1985), 273-284 (with T. R. S. Walsh)).
Most of the time, however, I worked on the design of a massively parallel processor to implement the GRC, or I worked on the GRC at the conceptual level, improving its transformation repertoire. (Generic reduction computers, Congressus Numerantium 54 (1986), 21-38), (Logical problems arising in the specification of a generic reduction computer, SPOCC (Special Problems in Communication and Computation) Workshop, Bell Communications Research, Morristown, N. J. Aug 1985), (Generic reduction computers, Computer Architecture Technical Committee Newsletter, IEEE Computer Society, March 1986, 25-47). Obviously, I could have taken the whole thing much further had the Scientific American column not come my way.
Although I am not in a position to prophecy with any confidence, I like to think that the mathematics of the future will address the general equivalence problem from a variety of standpoints: P-time equivalence, computational equivalence, transformational equivalence. Continuing the fantasy, the field as a whole will put a kind of squeeze on mathematics itself, reducing many fields to "essential" or "canonical" ingredients, erasing to a large degree the boundaries between fields and producing, in the process, a whole new way of thinking about (and within) mathematics. Who could want more than that?
In the meantime, I have slipped quietly into inductive science by pursuing what I call the holy grail of ecology. How are the abundances of species distributed? Although I do a considerable amount of analysis - both classical and statistical - and although I do a lot of computer programming, I find my findings depend heavily on experimental data. How did a Platonist come to such a pass?