The University of Western Ontario
London, Canada
Department of Computer Science
CS4402B/CS9635B -- Parallel and Distributed Computing
Winter 2022
Course Description
The efficient usage of parallel and distributed systems
(multi-processors and computer networks) is nowadays
an essential task for computer scientists.
This course studies the fundamental aspects of
parallel systems and aims at providing an integrated view of the various
facets of software development on such systems:
hardware architectures,
programming languages and models,
software development tools,
software engineering concepts and design patterns,
performance modelling and analysis,
experimenting and measuring,
application to scientific computing.
Course topics may include but are not limited to:
hierarchical memory, cache complexity,
multi-core and many-core architectures,
fork-join parallelism, scheduling,
scalability, GPU computing, data parallelism, pipelining,
message passing (MPI), parallel and distributed data-structures,
and applications of parallel and distributed computing.
Follow this link for various resources
(software tools and tutorials, hardware documentation,
conferences, other HPC course web sites, etc.)
regarding
this course and HPC in general.
Instructor
| Name: | Marc Moreno-Maza |
| Office: | MC 327 |
| Office Hours: | Monday 14:30 - 15:30 or by appointment |
| Email: | moreno@csd.uwo.ca |
| Phone: | 661-2111 x3741 |
Lecture Notes and Textbook
Notes of each lecture will be available on the course website,
approximately one or two days after the oral presentation.
The following textbooks are recommended but not required:
-
Structured Parallel Programming
by Michael McCool, Arch Robison, James Reinder.
-
C++ Concurrency
in Action, practical multithreading
by Anthony Williams
-
Programming language pragmatics (Chapter 12 only) by Michael L. Scott
-
Models of Computation Exploring the Power of Computing by John E. Savage.
OWL Website
For both CS4402 and CS9635, the OWL web site is
here.
Please check the course and OWL sites often for updates on lecture notes and errata, as well as the
forum discussions and announcements.
Also be aware that
the course website is not a substitute for the actual classroom attendance!
Course outline
Please find the course outline
here.
Lecture Topics
The list of topics will be something on the order of:
-
Overview of parallel and distributed computing
-
Parallel and distributed patterns in Julia:
- Rough installation notes for Jupyter and Julia
- my css customization file for Jupyter
- image for blocked matrix multiplication
- Julia basics: functions, methods, constructors and macros
- Asynchronous programming and distributed programming in Julia
- arrays and shared arrays in Julia
-
Hierarchical memories, cache complexity
Extra materials used in the lectures:
- Animation of naive counting sort
- Animation of counting sort using buckets
- Animation of various transposition algorithms
- C programs for matrix multiplication.
-
The fork-join model and the cilk concurrency platform
Extra materials used in the lectures:
- The OpenCilk web site
- The OpenCilk Tutorial at SPAA 2020
- OpenCilk examples
- Rough installation notes for OpenCilk and the above examples.
- Intel Cilk++ Programmers Guide
-
Parallel Random-Access Machines
-
Dependence Analysis and (Automatic) Parallelization
-
Many-core Computing with CUDA.
slides (Part 1) and
slides (Part 2). and
simple CUDA programs and
Polybench and
CUDA demo.
-
Programming parallel patterns with C++ 11
slides
-
Multiprocessed parallelism, message passing (MPI):
-
A Comprehensive MPI Tutorial Resource
- MPI intro lecture by Jon Eyolfson,
- MPI: Beyond the Basics by David McCaughan.
- MetaFork: A Compilation Framework for
Concurrency Platforms Targeting Multicores
slides
Class Schedule
Lectures: 3 hours (Tuesdays 12:30 - 13:30
and Thursdays 11:30 - 13:30)
When lectures are in-person, all lectures take place
in TC 343.
When lectures are on-like follow this link
on Tuesdays and that link
on Thursdays.
Each student is expected to attend the lectures. In particular,
quizzes (short written tests) may take place without notice.
Assignment/Project/Quiz Schedule
All dates are tentative and currently subject to change, although it is
doubtful by any significant amount.
| Evaluation Technique |
Weight |
Posted Date (tentative!) |
Due Date (tentative!) |
Workload |
| Assignment One | 1/6 | Jan. 27 | Feb. 18 | regular |
| Assignment Two | 1/6 | Feb. 18 | March 7 | regular |
| Project | 1/3 | March 7 | See above | heavy |
| Quizzes | 1/9 each | N/A | various | N/A |
Problem Sets for 2021-2022
Problem set 1
Problem set 2
Quiz corrections from 2014-2015
Quiz 1: elements of corrections for a 2014 quiz.
A CUDA quiz and its
elements of correction.
2015 Quiz 2 with elements of corrections.
Quiz corrections from 2016-2017
Quiz 1 with elements of corrections.
Quiz 2 with elements of corrections.
CS4402 projects in 2021-2022
Please find here the schedule
of the CS4402 project presentations for the Winter 2022 ter,.
Please find below papers that can be chosen for the course projects
of CS4402.
- Parallel Algorithms for maximum subsequence and maximum subarray
paper (selected)
- Fixing Performance Bugs: An Empirical Study of Open-Source GPGPU Programs
paper (selected)
- Register Spilling and Live-Range Splitting for SSA-Form Programs paper
- Beyond nested parallelism: tight bounds on work-stealing overheads for parallel futures paper (selected)
- Expressing pipeline parallelism using TBB constructs: a case study on what works and what doesn't paper (selected)
- On-the-Fly Pipeline Parallelism paper (selected)
- Pipelining with futures paper (selected)
- Tapir: Embedding Fork-Join Parallelism into LLVM's Intermediate Representation paper (selected)
- AUTOGEN: automatic discovery of cache-oblivious parallel recursive algorithms for solving dynamic programs paper
- GPU-ABiSort: optimal parallel sorting on stream architectures
paper
- Optimizing Graph Algorithms for Improved
Cache Performance paper (selected)
- An efficient parallelization strategy for dynamic programming on GPU paper (selected)
- Efficient Processing of Large Data Structures on GPUs:
Enumeration Scheme Based Optimisation paper(selected)
- Automatic Restructuring of GPU Kernels
for Exploiting Inter-thread Data Locality
paper
- A Performance Analysis Framework for Identifying
Potential Benefits in GPGPU Applications
paper
- Memory-level and Thread-level Parallelism Aware GPU Architecture Performance Analytical Model
paper
- Optimal Loop Unrolling For GPGPU Programs
paper (selected)
- In-Place Matrix Transposition on GPUs
paper
-
Dynamic Programming Parallel Implementation for the Knapsack problem
paper (selected)
- Parallelizing MiniSat
report (selected)
- Sorting algorithms in CUDA (literaure review and comparative
experimentation)
paper (selected)
- prefix sum algorithms in CUDA (literaure review and comparative experimentation)
wikipedia
and
one paper to start with (selected)
- Cross-loop Reuse Analysis and its Application to Cache Optimizations paper
- The Tao of Parallelism in Algorithms
paper (selected)
- Perfect Pipelining: A New Loop Parallelization Technique
paper (selected)
-
paper
-
-
-
Marc Moreno Maza
Last modified: Mon Jan 10, 2022
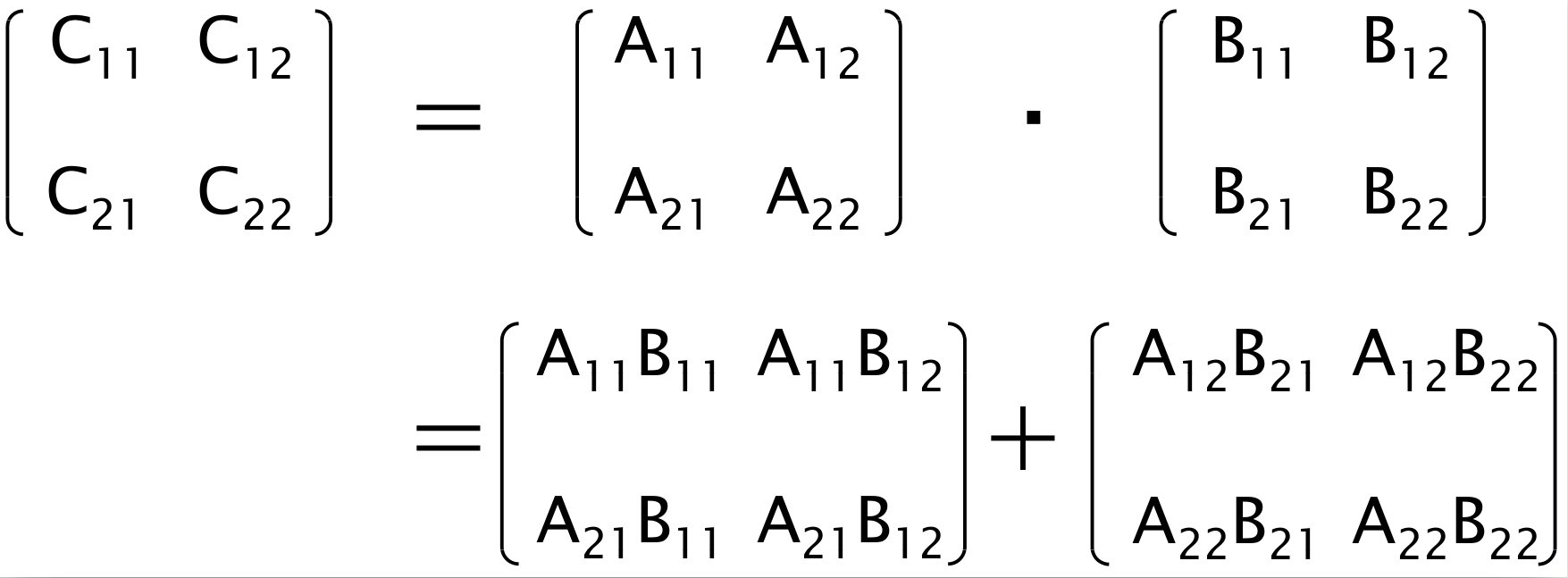{kind=link}